Установка Okagent
Документация по установке будет доступна после создания проекта.
При использовании брандмауэра необходимо добавить следующие IP-адреса в список разрешенных: ip.txt.Встроенные плагины
Okmeter автоматически собирает метрики со следующих программных и аппаратных компонентов:- CPU usage
- Load average
- Memory
- Swap: утилизация, I/O
- Disks: утилизация, I/O
- По всем процессам: CPU, RAM, SWAP, Disk I/O, open files
- TCP соединения: states, ACK backlog, RTT
- Memcached
- Redis
- NGINX Access Log
- Raid
- Zookeeper
Настройка NGINX
Для корректной работы Okagent требуется определенный формат логов доступа NGINX. Для настройки необходимо выполнить следующие действия:- Добавьте:
log_format(или измените существующий) в/etc/nginx/nginx.conf:
http {
...
log_format combined_plus '$remote_addr - $remote_user [$time_local]'
' "$request" $status $body_bytes_sent "$http_referer"'
' "$http_user_agent" $request_time $upstream_cache_status'
' [$upstream_response_time]';
...
}
access_log в конфигурационных файлах NGINX.
Как правило, изменения достаточно внести только в
/etc/nginx/nginx.conf:
http {
...
access_log /var/log/nginx/access.log combined_plus;
...
}
sudo /etc/init.d/nginx reload
Если формат не указан, будет использоваться формат по умолчанию
combined. Данный формат не содежит переменные $request_time, $upstream_cache_status, и $upstream_response_time. Необходимо найти все директивы access_log и указать формат, содержащий все необходимые переменные.
PostgreSQL
При использовании облачного PostgreSQL (Amazon AWS RDS, AWS Aurora Postgres, Google Cloud SQL, Azure Database, Yandex Cloud Postgres) проведите предварительную настройку, после чего вернитесь к данному разделу и выполните все действия, описанные ниже.Для мониторинга PostgresSQL необходимо создать отдельного пользователя. Okagent будет использовать этого пользователя для подключения к инстансу базы данных. Кроме того, необходимо создать дополнительные функции в базе данных
postgres, необходимые для сбора мониторинговых данных. Чтобы создать пользователя и добавить функции, выполните следующие команды:
$ sudo su postgres -c "psql -d postgres"
CREATE ROLE okagent WITH LOGIN PASSWORD 'EXAMPLE_PASSWORD_DONT_USE_THAT_please_!)';
CREATE SCHEMA okmeter;
GRANT USAGE ON SCHEMA okmeter TO okagent;
CREATE OR REPLACE FUNCTION okmeter.pg_stats(text)
RETURNS SETOF RECORD AS
$$
DECLARE r record;
BEGIN
FOR r IN EXECUTE 'SELECT r FROM pg_' || $1 || ' r' LOOP RETURN NEXT r; -- To get pg_settings, pg_stat_activity etc.
END loop;
RETURN;
END
$$ LANGUAGE plpgsql SECURITY DEFINER;
Далее необходимо разрешить подключение Okagent к инстансу базы данных. Для этого отредактируйте файл
pg_hba.conf (pg_hba.conf docs) и добавьте в него следующие строки:
host all okagent 127.0.0.1/32 md5
local all okagent md5
Для облачных PostgreSQL (Yandex Cloud Postgres, Amazon AWS RDS, AWS Aurora Postgres, Google Cloud SQL, Azure Database, и прочих) измените
127.0.0.1 в pg_hba.conf на IP адрес сервера, где запущен Okagent.
Чтобы применить изменения в pg_hba.conf, выполните следующие команды:
$ sudo su postgres -c "psql -d postgres"
SELECT pg_reload_conf();
Все готово!
Статистка запросов PostgreSQL
Для сбора статистики SQL-запросов в реальном времени и статистики выполнения запросов необходимо включить расширение pg_stat_statements.Это стандартное расширение разработано сообществом Postgres. На данный момент оно хорошо протестировано, стабильно работает и доступно в большинстве облачных баз данных.
При использовании Postgres версии 9.6 и старше установите пакет
postgres-contrib с помощью менеджера пакетов вашего дистрибутива Linux. Также его можно скачать с сайта postgresql.org.
Далее расширение необходимо настроить в Postgres. Для этого добавьте следующие строки в
postgresql.conf:
shared_preload_libraries = 'pg_stat_statements' # change requires DB restart.
pg_stat_statements.max = 500
pg_stat_statements.track = top
pg_stat_statements.track_utility = true
pg_stat_statements.save = false
Также можно включить тайминг для операций ввода/вывода (прежде ознакомьтесь с документацией Postgres по настройке статистики времени выполения. Для этого добавьте следующие строки в postgresql.conf:
track_io_timing = on
Для применения настроек необходимо перезапустить Postgres:
$ sudo /etc/init.d/postgresql restart
Теперь необходимо активировать расширение. Для этого выполните следующие команды:
$ sudo su postgres -c "psql -d postgres"
CREATE EXTENSION pg_stat_statements;
PgBouncer
Для мониторинга PgBouncer необходимо добавить пользователяokagent в /etc/pgbouncer/userlist.txt (или в файл, указанный в директиве auth_file в pgbouncer.ini):
если у PgBouncer auth_type = md5
"okagent" "EXAMPLE_PASSWORD_DONT_USE_THAT_please_!)"
если у PgBouncer auth_type = scram-sha-256 (хеш может меняться при обновлении страницы, но все хеши валидны, нет необходимости обновлять их в конфиге pgbouncer)
"okagent" "EXAMPLE_PASSWORD_DONT_USE_THAT_please_!)"
Далее необходимо добавить stats_user в pgbouncer.ini:
; comma-separated list of users who are just allowed to use SHOW command
stats_users = okagent
Для применения настроек перезапустите PgBouncer:
/etc/init.d/pgbouncer reload
JVM
Для мониторинга JVM необходимо включить JMX. Для этого добавьте следующие аргументы к аргументам запуска JVM:-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.host=127.0.0.1 -Djava.rmi.server.hostname=127.0.0.1 -Dcom.sun.management.jmxremote.port=9099 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
Q: Что, если на сервере запущено больше одного JVM?
A: Можно указать разные порты JMX для каждого JVM процесса. Если JVM запускается с параметрами `authenticate=false` и `ssl=false`, Okagent будет автоматически собирать данные мониторинга.
Php-fpm
Для мониторинга php-fpm необходимо включить status page для всех php-fpm pool. Раскомментируйте директивуpm.status_path для всех php-fpm pool во всех файлах .conf и установите URL для status page:
pm.status_path = /status ;you can use /status or any other url, okagent will work with thatПерезапустите php-fpm, чтобы применить настройки:
service php-fpm restart или docker restart some-php-container. После этого Okmeter начнет собирать статистику по php-fmp pools.
RabbitMQ
Для мониторинга RabbitMQ необходимо включить плагин rabbitmq_management и создать пользователя для Okagent. Чтобы сделать это, выполните следующие команды на всех серверах RabbitMQ:rabbitmq-plugins enable rabbitmq_management
rabbitmqctl add_user okagent EXAMPLE_PASSWORD_DONT_USE_THAT_please_!)
rabbitmqctl set_user_tags okagent monitoring
И предоставьте права пользователю okagent на доступ к vhosts:
rabbitmqctl set_permissions -p / okagent ".*" ".*" ".*" rabbitmqctl set_permissions -p /vhost1 okagent ".*" ".*" ".*"Список
vhosts можно вывести следующей командой:
rabbitmqctl list_vhosts
Mysql
Для мониторига Mysql необходимо создать отдельного пользователя для подключения к инстансу базы данных. Для этого выполните следующие команды:
CREATE USER 'okagent'@'%' IDENTIFIED BY 'EXAMPLE_PASSWORD_DONT_USE_THAT_please_!)';
GRANT PROCESS, REPLICATION CLIENT ON *.* TO 'okagent'@'%';
GRANT SELECT ON `performance_schema`.* TO 'okagent'@'%';
FLUSH PRIVILEGES;
Для сбора статистики по запросам MySQL Okmeter использует таблицу events_statements_summary_by_digest в схеме performance_schema, которая есть во всех современных версиях MySQL, Percona и MariaDB. Для проверки совместимости выполните команду:
mysql> SELECT 'OK' FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA='performance_schema' AND TABLE_NAME='events_statements_summary_by_digest'; +----+ | OK | +----+ | OK | +----+Если результат выполнения запроса "OK", необходимо проверить, что
performance_schema включена и инициализирована. Для этого выполните команды:
mysql> SHOW VARIABLES LIKE 'performance_schema'; +--------------------+-------+ | Variable_name | Value | +--------------------+-------+ | performance_schema | ON | +--------------------+-------+Если результат запроса "OFF", необходимо включить
performance_schema в my.conf и перезапусить MySQL:
[mysqld] performance_schema=ONЕсли используется облачная разновидность MySQL (Yandex Cloud MySQL, Amazon AWS RDS, AWS Aurora Postgres, Google Cloud SQL, Azure Database, и прочих), воспользуйтесь данной инструкцией.
Внешние и облачные базы данных
Для мониторинга облачных и внешних баз данных (т.е. баз данных, которые находятся на хостах, на которых не установлен Okagent), можно установить Okagent на отдельный хост и настроить его соответствующим образом.
На настоящий момент поддерживаются следующие внешние и облачные базы данных: ElasticSearch, Redis, MySQL, PostgreSQL
На хосте, на котором установлен Okagent и у которого есть сетевой доступ к базе данных, необходимо для каждого инстанса базы данных создать конфигурационный файл в директории /usr/local/okagent/etc/config.d/ (например /usr/local/okagent/etc/config.d/remote_db.yaml) со следующим содержимым:
Для базы данных MySQL или PostgreSQL:
plugin: postgresql # или mysql config: host: db_ip # замените на IP удаленного инстанса БД или endpoint кластера #port: db_port # раскомментируйте и замените на порт удаленного инстанса БД, если тот нестандартный user: db_user # замените на имя мониторинг-пользователя удаленного инстанса БД password: db_password # замените на пароль мониторинг-пользователя удаленного инстанса БД #database: mydb # замените на имя базы данных, которую вы подключили при создании схемы okmeter, пользователя и функции в PostgreSQL, если оно отличается от "postgres" #sslmode: Задает режим подключения к postgresql sslmode: disable, allow, prefer, require, verify-ca, verify-full. Значение по умолчанию: Пытаеться подключиться в sslmode: disable, если не получается пробует в sslmode:require.
Для базы данных Redis:
plugin: redis config: host: db_ip # замените на IP удаленного инстанса БД или endpoint кластера #port: db_port # раскомментируйте и замените на порт удаленного инстанса БД, если тот нестандартный #password: db_password # раскомментируйте и замените на пароль мониторинг-пользователя удаленного инстанса БД
Для базы данных ElasticSearch
plugin: elasticsearch config: host: elasticserch_ip # замените на IP Elasticsearch в формате: xx.xx.xx.xx #port: db_port # раскомментируйте и замените на порт удаленного инстанса Elasticsearch, если тот нестандартный (9200) #user: db_user # раскомментируйте и замените на имя мониторинг-пользователя удаленного инстанса Elasticsearch #password: db_password # раскомментируйте и замените на пароль мониторинг-пользователя удаленного инстанса Elasticsearch #insecureTls: true # раскомментируйте, если Elasticsearch настроена на использование самоподписанного сертификата
Для применения настроек перезапустите Okagent: $ sudo /etc/init.d/okagent restart (или $ sudo systemctl restart okagent.service).
Убедитесь, что для базы данных произведены все необходимые дополнительные настройки (см. документацию Mysql или Postgresql).
Zookeeper
Для мониторига Zookeeper версии 3.4.10 и выше необходимо добавить командыstat и mntr в список разрешенных. Для этого включите следующую строку в конфигурационный файл zoo.cfg:
4lw.commands.whitelist=stat, mntr
Пользовательские метрики
В дополнение к встроенным метрикам Okagent может отправлять кастомные метрики. Есть несколько способов генерации таких метрик :
- Написать SQL запрос, который возвращает цифровые значения, воспользовавшись плагином SQL query.
- Производить парсинг файлов логов с помощью плагина Logparser.
- Написать скрипт, который генерирует метрики, и вызывать его с помощью плагина Execute.
- Производить парсинг ответа на HTTP-запрос с помощью плагина HTTP.
- Генерировать метрики на основе вывода Redis-команд, воспользовавшись плагином Redis query.
- Собирать метрики с приложения с помощью Statsd.
- Собирать метрики с Promethus-совместимых экспортеров, воспользовавшись плагином Prometheus
Эти плагины требуют дополнительной настройки с помощью конфигурационных файлов. Okagent при запуске читает все конфигурационные файлы в каталоге /usr/local/okagent/etc/config.d/. Имя конфигурационного файла может быть любым, расширения всегда должно быть .yaml, формат файла — YAML.
Проверка конфигурационных файлов | режим dry run
Синтаксис кофигурационного файла можно проверить с помощью следующей команды (замените PLUGIN_CONFIG_FILE на свой файл):
$ /usr/local/okagent/okagent -dry-run=/usr/local/okagent/etc/config.d/PLUGIN_CONFIG_FILE
Если в результате выполения комманды не возникло ошибок, примените конфигурационный файл, перезапустив Okagent: $ sudo /etc/init.d/okagent restart (или $ sudo systemctl restart okagent.service).
Плагин SQL query
Плагин SQL query отправляет метрики, собирая необходимую информацию с помощью периодических запросов в базу данных.
На настоящий момент этот плагин совместим с PostgreSQL, MySQL, Microsoft SQL Server и ClickHouse.
Пример. Допустим, в базе данных имеется таблица article_updates
update_type | character varying(16)
updated | timestamp without time zone
...
И нужно отслеживать количество новых update_type. Это можно сделать с помощью следующего запроса:
SELECT COUNT(*) AS value, update_type FROM labels WHERE updated BETWEEN NOW() - INTERVAL '60 seconds' AND NOW() GROUP BY update_type
Внимание: Предварительно проверьте план выполения запроса. Ежеминутные запросы могут оказать дополнительную нагрузку на базу данных.
Okagent будет периодически запрашивать необходимую информацию у базы данных. В итоге вы получите график следующего вида:
Внимание: Okmeter использует поле value в результате запроса как значение метрики (floating point). Все остальные значения из результата запроса будут добавлены к метрике как лейблы с соотвествующими именами.
Примеру выше соответствует конфигурационный YAML-файл плагина /usr/local/okagent/etc/config.d/article_updates.yaml следующего содержания:
plugin: postgresql_query # или mssql_query или mysql_query или clickhouse_query config: host: '127.0.0.1' port: 5432 db: some_db user: some_user password: secret query: "SELECT COUNT(*) AS value, update_type FROM labels WHERE updated BETWEEN NOW() - INTERVAL '60 seconds' AND NOW() GROUP BY update_type" metric_name: demo_documents_update_rateВ результате будет отправляться метрика с именем demo_documents_update_rate .
Внимание: Имена метрик и лейблов могут содержать только ASCII-символы и цифры и должны удовлетворять регулярному выражению [a-zA-Z_][a-zA-Z0-9_]*.
Внимание: Перед использованием нужно проверить корректность конфигурационного файла.
Внимание: Для применения настроек необходимо перезапустить Okagent: $ sudo /etc/init.d/okagent restart (или $ sudo systemctl restart okagent.service).
Плагин Execute
Этот плагин отправляет пользовательские метрики, созданные внешним процессом, на основание данных, полученных из его стандартного потока вывода. Для генерации метрик можно использовать два типа парсеров: Regexp или Json.
Regexp
Regexp-парсер анализирует строки, полученные в результате работы скрипта, и преобразует их в значение метрики и дополнительные наборы labelset. Например, для отправки метрики на основание выполнения команды du необходимо создать конфигурационный файл /usr/local/okagent/etc/config.d/app_log_disk_usage.yaml в формате YAML следующего вида:
plugin: execute
config:
command: 'du /var/log/app/main.log'
regexp: '(?P<value>\d+)'
name: demo_app_log_size # metric name
value: value # metric value
labels: # metric labels
log_name: main
В результате будет отправляться метрика с именем demo_app_log_size.
Внимание: Имена метрик и лейблов могут содержать только ASCII-символы/цифры и должны удовлятворять регулярному вырожению [a-zA-Z_][a-zA-Z0-9_]*.
Внимание: Перед использованием нужно проверить корректность конфигурационного файла.
Внимание: Для применения настроек необходимо перезапустить Okagent: $ sudo /etc/init.d/okagent restart (или $ sudo systemctl restart okagent.service).
JSON
JSON-парсер может использоваться для отправки уже подготовленных метрик или нескольких метрик одновременно.
Внимание: Результат вывода скрипта должен быть в формате JSON и обязательно содержать поля name и value; дополнительные лейблы должны быть перечислены в поле с именем labels:
{
"name": "metric1",
"labels": {"label1": "foo", "label2": "bar"},
"value": 123.4
}
Пример. Допустим, имеется Bash-скрипт calc_metrics.sh следующего содержания:
echo '{"name": "metric1", "labels": {"label1": "foo", "label2": "bar"}, "value": 123.4}'
Чтобы отправлять метрики с помощью плагина Execute и этого скрипта, необходимо создать конфигурационный YAML-файл /usr/local/okagent/etc/config.d/execute_json.yaml следующего вида:
plugin: execute config: command: /tmp/calc_metrics.sh parser: json
Пример. Скрипт, способный отправлять сразу несколько метрик, будет выглядеть так:
echo '[{"name": "metric1", "value": 123.4}, {"name": "metric2", "value": 567}]'
Внимание: Имена метрик и лейблов могут содержать только ASCII-символы и цифры и должны удовлетворять регулярному выражению [a-zA-Z_][a-zA-Z0-9_]*.
Внимание: Перед использованием необходимо проверить корректность конфигурационного файла.
Внимание: Для применения настроек необходимо перезапустить Okagent: $ sudo /etc/init.d/okagent restart (или $ sudo systemctl restart okagent.service).
Плагин Logparser
Данный плагин отправляет метрики, полученные из файла логов. Для генерации метрик можно использовать парсеры Regexp или JSON.
Regexp
Regexp-парсер анализирует каждую строку файла и преобразует ее в значение метрики и дополнительные наборы labelset. Например, для отправки метрики на базе файла логов/var/log/app/stages.log необходимо создать конфигурационный YAML-файл /usr/local/okagent/etc/config.d/stage_log.yaml следующего вида:
plugin: logparser config: file: /var/log/app/stages.log regexes: # 2015-11-21 15:42:36,972 demo [DEBUG] page=item stages: db=0.007s, render=0.002s, total=0.010s count=1 - regex: '(?P\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}).+ page=(?P \w+) stages: db=(?P \d+\.\d+)s, render=(?P \d+\.\d+)s, total=(?P \d+\.\d+)s count=(?P \d+)' time_field: datetime time_field_format: '2006-01-02 15:04:05' metrics: ...
- file — путь до файла, который будет анализироваться. Okagent корректно обрабатывает ротацию файлов.
- regexes — список регулярных выражений, которые будут применены к строкам. Регулярные выражения применяются последовательно.
- regexp — поле, в котором задается Perl-совместимое регулярное выражение(
regex), на основании которого строка будет разделена на именованные группы для дальнейшей трансформации в метрики.
- regexp — поле, в котором задается Perl-совместимое регулярное выражение(
- time_field — имя группы для временных меток.
- time_field_format — формат временных меток.
- metrics — список метрик, которые должны быть отправлены, вместе с правилами трансформации строк в метрики.
JSON
JSON-парсер преобразовывает логи в формате JSON в метрики. Данный способ предпочтителен, поскольку создает меньшую нагрузку и не требует парсинга на базе регулярных выражений.
plugin: logparser
config:
file: /var/log/app/stages.log
json: true
# {ts: "2015-11-21 15:42:36.000+0300", user: "demo", page: "item", db: "0.007", render: "0.002", total: "0.010", count: "1"}
time_field: ts
time_field_format: "2006-01-02 15:04:05.000-0700"
metrics:
...
- file — путь до анализируемого файла. Okagent корректно обрабатывает ротацию файлов.
- json — поле, определяющее тип парсера (JSON).
- time_field — имя группы для временных меток.
- time_field_format — формат временных меток.
TOP
Парсинг логов часто приводит к большому "оттоку" (churn) метрик, что негативно сказывается на отображении графиков. Для метрик на основе файлов логов рекомендуется использовать функцию TOP. Она позволяет получить N метрик (параметр N задается в конфигурационном файле), при этом все остальные метрики суммируются и отправляются в виде дополнительной метрики со значением label: ~other.
Пример. Производится парсинг лог-фала /var/log/app/stages.log, в котором содержится информация о запросах пользователей к сервису. Требуется отправлять метрики только по десяти запросам, которые чаще всего встречались за последние 10 минут. Для реализации этой схемы необходимо создать конфигурационный YAML-файл /usr/local/okagent/etc/config.d/top_url.yaml следующего вида:
plugin: logparser
config:
file: /var/log/app/stages.log
#{"ts":"2018-09-12 13:07:11.500","logger": "requests","time":"33","method":"PUT","status":200,"uri":"/aaa/bbb","rid":noRequestId,ip":"2.2.2.2"}
#{"ts":"2019-11-20 18:32:49.851+0300","logger":"requests","time":"157","method":"PUT","status":200,"uri":"/foo/bar?from=header_new","rid":"11","ip":"1.1.1.1"}
json: true
time_field: ts
time_field_format: "2006-01-02 15:04:05.000-0700"
top_vars:
topurl:
source: uri
weight: 1
threshold_percent: 1
window_minutes: 10
metrics:
- type: rate
name: service_requests_rate
labels:
method: =method
url: =topurl
status: =status
- type: percentiles
name: service_response_time_percentiles
value: ms2sec:time
args: [50, 75, 95, 99]
- type: percentiles
name: service_response_time_percentile_by_url
value: ms2sec:time
args: [95]
labels:
url: =topurl
В разделе top_vars есть следующие поля:
topurl— новый лейбл для метрики, по которому будет производиться получение TOPN URIs (JSON-поле –source: uri).weight— вес, на который будет изменяться счетчик при каждом вхождении для URI.threshold_percent— метрики, процент которых в общей сумме ниже этого порогового значения, объединяются в специальную кумулятивную метрику (~other).window_minutes— размер окна, в рамках которого производится подсчет TOP.
type задает тип метрики и может принимать следующие значения:
-
rate— средняя скорость роста метрики в минуту. Является значением по умолчанию. -
percentile— процентиль для метрики. Полеargs— массив желаемых процентилей, например:[50, 95, 99]. -
maxилиmin— отправляет максимальное или минимальное значение для метрики за минуту. -
threshold— собирает количество попаданий значенияvalueв различные интервалы (например,(-∞, 0.5],(0.5, 1], ...).
time_field — имя группы для хранения временных меток.
time_field_format — формат временных меток. Возможные форматы:
unix_timestamp— временные метки в формате Unixcommon_log_format— временные метки в формате2/Jan/2006:15:04:05 -0700time_iso8601— временные метки в формате RFC 3339 (также ISO 8601)- Кастомный формат временных меток. Пользователь сам определяет, как контрольное время — например,
Mon Jan 2 15:04:05 -0700 MST 2006— будет приведено к формату лога. Служит примером для плагина Logparser.
При отсутствии информации о часовом поясе используется часовой пояс UTC.
Поле metric может содержать поле labels, значениями которого могут выступать статические (stage: db) или динамические (page: =page) лейблы. Знак равенства = перед значением лейбла (как в примере выше — page: =page) означает, что значение этого лейбла должно быть взято из regexp-группы с именем page.
Прмер. Предположим, что лог приложения содержит следующие записи:
... 2015-11-01 22:51:44,072 demo [DEBUG] page=item stages: db=0.005s, render=0.002s 2015-11-01 22:51:44,087 demo [DEBUG] page=list stages: db=0.003s, render=0.001s ...
Если применить приведенный ниже конфигурационный файл,..
plugin: logparser
config:
file: /var/log/app/stages.log
regexes:
# 2015-11-21 15:42:36,972 demo [DEBUG] page=item stages: db=0.007s, render=0.002s, total=0.010s count=1
- regex: '(?P<datetime>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}).+ page=(?P<page>\w+) stages: db=(?P<db>\d+\.\d+)s, render=(?P<render>\d+\.\d+)s, total=(?P<total>\d+\.\d+)s count=(?P<count>\d+)'
time_field: datetime
time_field_format: '2006-01-02 15:04:05'
metrics:
- type: percentiles
args: [50, 75, 95, 98, 99]
value: db
name: demo_stages_percentiles
labels:
stage: db
- type: percentiles
args: [50, 75, 95, 98, 99]
value: render
name: demo_stages_percentiles
labels:
stage: render
- type: rate
name: demo_requests_rate
labels:
page: =page
- type: rate
name: demo_documents_rate
value: count
labels:
page: =page
- type: threshold
value: total
args: [0.05, 0.1]
name: demo_render_histogram
labels:
page: =render
... плагин Logparser будет отправлять следующие метрики: demo_requests_rate, demo_documents_rate, demo_stages_percentiles and demo_render_histogram.
Внимание: Перед использованием проверьте корректность конфигурационного файла.
Внимание: Для применения настроек перезапустите Okagent: $ sudo /etc/init.d/okagent restart (или $ sudo systemctl restart okagent.service).
Плагин HTTP
Этот плагин отправляет пользовательские метрики о доступности HTTP-сервиса, а так же метрики, полученные в результате парсинга ответа на HTTP-запроса.
Пример. Есть HTTP-сервис, доступ к которому ограничен Basic Auth. Ответ на запрос к URL /service/stat выглядит следующим образом:
curl --user name:password -H 'Foo: bar' -v 'http://127.0.0.1:8080/service/stat' > GET /service/stat HTTP/1.1 > Host: 127.0.0.1 > Authorization: Basic bmFtZTpwYXNzd29yZA== > Foo: bar > < HTTP/1.1 200 OK < online_users=140 active_users=10
Для отправки пользовательских метрик, полученных в результате парсинга ответа на HTTP-запрос, необходимо создать конфигурационный файл /usr/local/okagent/etc/config.d/http.yaml в формате YAML:
plugin: http config: url: http://127.0.0.1:8080/service/stat username: name password: password #sslskip: on #optional, disable certificate verification, like curl --insecure headers: foo: bar metrics: - metric: users_online regex: 'online_users=(\d+)' - metric: users_active regex: 'active_users=(\d+)'
Запрос будет выполняться каждую минуту, и по результатам парсинга полученного ответа будут отправляться следующие метрики:
metric(name="users_online") metric(name="users_active")
Кроме того, будут отправляться три дополнительные метрики:
metric(name="status", plugin="http", instance="<config filename>")
Со значением "1", если запрос был выполнен успешно, и "0" — в противном случае.
metric(name="status", plugin="http", instance="<config filename> type="text", value="")
Значение лейбла value будет пустым, если запрос был выполнен без ошибок. В противном случае в значении поля value будет указана ошибка, которая возникла в процессе выполнения запроса.
metric(name="http.request_time", plugin="http", instance="<config filename>")
В качестве значения этой метрики будет передаваться время выполения запроса.
Внимание: Имена метрик и лейблов могут содержать только ASCII-символы и цифры и должны удовлятворять регулярному выражению [a-zA-Z_][a-zA-Z0-9_]*.
Внимание: Перед использованием проверьте корректность конфигурационного файла.
Внимание: Для применения настроек перезапустите Okagent: $ sudo /etc/init.d/okagent restart (или $ sudo systemctl restart okagent.service).
Плагин Redis query
Этот плагин позволяет отправлять кастомные метрики, полученные в результате выполения команд Redis. Пример конфигурационного файла /usr/local/okagent/etc/config.d/redis_example.yaml приведен ниже:
plugin: redis_query config: #host: 127.0.0.1 #optional #port: 6379 #optional #database: 0 #optional commands: - LLEN achievement_queue - SCARD some_queue - HGET stat active_connections - GET mail_sender_queue_lenПлагин с такой конфигурацией будет отправлять четыре метрики:
metric(name="achievement_queue.llen") metric(name="some_queue.scard") metric(name="stat.hget", param="active_connections") metric(name="mail_sender_queue_len.get")Поддерживаются следующие команды Redis: BITCOUNT, GET, GETBIT, GETRANGE, HGET, HLEN, HSTRLEN, LINDEX, LLEN, PTTL, SCARD, STRLEN, TTL, ZCARD, ZCOUNT, ZLEXCOUNT, ZRANK, ZREVRANK, ZSCORE.
StatsD / Метрики приложения
Что это такое
Для большинства языков разработки существуют готовые библиотеки statsd client libraries. С их помощью можно легко отправлять метрики из приложения, такие как счетчики и таймеры, агенту Okagent по UDP. Okagent будет агрегировать полученные метрики и пересылать их в Okmeter для дальнейшего отображения и создания триггеров.
Okagent принимает UDP-подключения на порт 8125 и обрабатывет метрики StatsD типа counts, timings и gauges.
Пример отправки метрик из приложения по протоколу StatsD
Ниже приведен пример использования библиотеки pystatsd в веб-приложении, написанном на Python:
from statsd import StatsClient statsd_client = StatsClient(host='127.0.0.1', port=8125, prefix='demo') def item(*args, **kwargs): statsd_client.incr('view.get.demo.views.item.hit') #what a long metric name! return Items.get()
В результате будут отправляться следующие метрики:
metric(source_hostname="backend1", name="demo.view.get.demo.views.item.hit", …) #equals to call count of "item" function metric(source_hostname="backend1", name="demo.view.get.demo.views.item.hit.rate", …) #and this is calls per second rate
На основании этих метрик можно построить следующие графики:
Также можно измерять скорость работы функций или отдельных частей функций — для этого есть специальный тип Timers:
def list(*args, **kwargs):
with statsd_client.timer('view.get.demo.views.list.total'):
return get_list_with_some_work()
В результате будут отправляться следующие метрики:
metric(name="demo.view.get.demo.views.list.total.mean", …) metric(name="demo.view.get.demo.views.list.total.count", …) metric(name="demo.view.get.demo.views.list.total.lower", …) metric(name="demo.view.get.demo.views.list.total.upper", …) metric(name="demo.view.get.demo.views.list.total.percentile", percentile="50", …) metric(name="demo.view.get.demo.views.list.total.percentile", percentile="75", …) metric(name="demo.view.get.demo.views.list.total.percentile", percentile="90", …) metric(name="demo.view.get.demo.views.list.total.percentile", percentile="95", …) metric(name="demo.view.get.demo.views.list.total.percentile", percentile="97", …) metric(name="demo.view.get.demo.views.list.total.percentile", percentile="99", …)
На основании этих метрик можно построить следующие графики:
Рекомендации по использованию StatsD
В реальных проектах могут быть сотни, а иногда и тысячи метрик. При таком их количестве крайне важно именовать метрики правильно. Это позволит удобно и быстро строить различные графики. Мы часто сталкиваемся с тем, что пользователи пытаются минимизировать количество лейблов и вынести всю информацию в имя метрики, например myapp.some.really.long.metrics.names или some.other.long.metric.name. При построении графиков приходится указывать полное имя метрики, что зачастую трудоемко и усложняет описание графиков и триггеров. Кроме того, при появлении новой метрики потребуется вносить изменения в график.
Мы рекомендуем использовать стандарт Metrics 2.0.
В этом случае вместо метрики с именем demo.view.get.demo.views.list.total.mean рекомендуется отправлять метрику следующего вида:
metric(name="demoapp.view.timing.mean", phase="total", handler="search", method="get")
В общем случае name метрики должно указывать на конкретную цель измерения (в нашем примере это view.timing). Уточняющие данные следует выносить в лейблы данной метрики.
Ниже приведен пример возможной реализации при использовании StatsD:
stats = StatsClient(host='127.0.0.1', port=8125, prefix='demoapp') def search(request): with stats.timer('view.timing.phase_is_total.handler_is_search.method_is_'+request.method): return get_list_with_some_work() def get_item(*args, **kwargs): with stats.timer('view.timing.phase_is_total.handler_is_get_item.method_is_'+request.method): return get_list_with_some_work()
Добавить лейблы tag_1 со значением some_value и tag_2 со значением other_val к метрике с именем
my.precious.metric можно следующим образом: my.precious.metric.tag_1_is_some_value.tag_2_is_other_val.
Порядок лейблов не имеет значения. Вариант my.precious.metric.tag_2_is_other_val.tag_1_is_some_value ничем не уступает первому и тоже будет работать.
Не рекомендуется использовать большое количество различных значений для одного лейбла. Например, сохранять полный URL в качестве значения лейбла — плохая идея, поскольку ведет к отправке большого количества метрик и негативно влияет на скорость отображения. Кроме того, обычно это не имеет смысла.
Рекомендуется использовать не более 5 лейблов для каждой метрики и определять не более 10 различных значений для каждого лейбла.
Расширенная настройка
По умолчанию Okagent принимает UDP-запросы на порт 8125. Если данный порт недоступен, его можно переопределить, создав конфигурационный файл /usr/local/okagent/etc/config.d/statsd.yaml:
plugin: statsd config: listen_address: "192.168.1.1:18125" gauge_age_threshold_seconds: 3600 # кол-во секунд, по истечению которых необновляемые gauges будут удалены из памяти
Внимание: Перед использованием проверьте корректность конфигурационного файла.
Внимание: Для применения настроек перезапустите Okagent: $ sudo /etc/init.d/okagent restart (или $ sudo systemctl restart okagent.service).
Плагин Prometheus
Данный плагин позволяет собирать данные с Prometheus-совместимых экспортеров и отправлять их в виде метрик.
Для приложений, запущенных в Kubernetes, обнаружение (discovering) производится с помощью аннотаций:
apiVersion: apps/v1 kind: Deployment #or StatefulSet, DaemonSet, CronJob, ... metadata: name: my-app annotations: prometheus.io/scrape: "true" prometheus.io/scheme: "http" prometheus.io/port: "80" prometheus.io/path: "/metrics" ...
Okagent также может производить discovering для приложений, запущенных в Docker-контейнерах, у которых установлены соответствующие лейблы:
docker run --name my-app \ --label io.prometheus.scrape=true \ --label io.prometheus.port=80 \ --label io.prometheus.scheme=http \ --label io.prometheus.path="/metrics" \ ...
Okagent способен собирать данные с пользовательских targets, описанных в конфигурационном файле. Сбор данных производится, пока Okagent получает корректные ответы. Пример конфигурационного файла плагина приведен ниже:
plugin: prometheus config: targets: - http://localhost:9100/metrics # max cardinality (default 5000) limit: 1200 # additional labels for all scraped metrics labels: exporter: node
При необходимости можно указать данные для аутентификации. На текущий момент поддерживается Basic Authorization и аутентификация на базе Bearer-токенов
plugin: prometheus config: targets: - http://localhost:9100/metrics authorization: type: basic username: <user> password: <password>
Пример конфигурационного файла с использование Bearer-токена:
plugin: prometheus config: targets: - http://localhost:9100/metrics authorization: type: bearer token: <token>
API
В Okmeter встроена ограниченная поддержка API Prometheus. На настоящий момент поддерживаются два типа запросов: query и query_range.
Okmeter можно подключить как Datasource в инсталяцию Grafana. Для этого необходимо добавить новый Datasource типа Prometheus со следующими настройками:
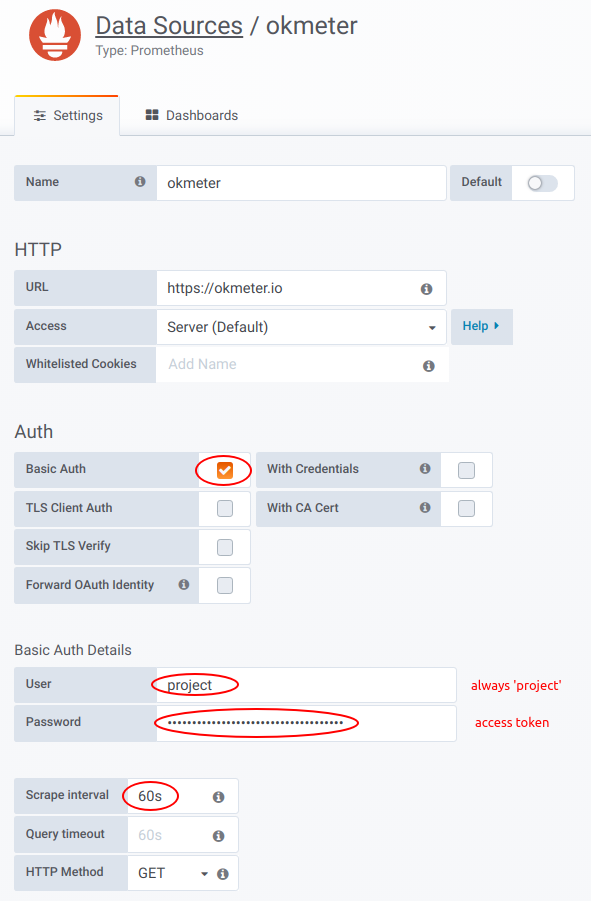
В качестве Basic Auth Password необходимо использовать токен доступа . Важно установить Scrape interval, равный 60s.
После настройки этот Datasource можно использовать для получения данных из Okmeter.
На настоящий момент Okmeter не поддерживает язык запросов PromQL. Поддерживается только собственный язык запросов Okmeter Query Language.
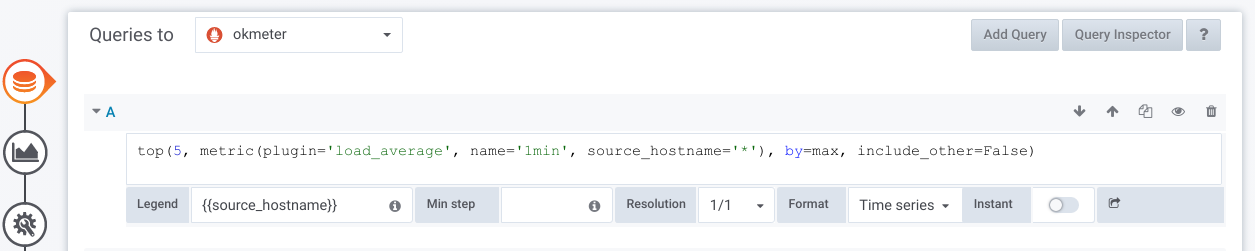
Query Language
Синтаксис lines-выражений:
lines: - expression:
metric(a='b', c='d*', e=['f', 'g*'])#пример с различными load averages- получить список всех метрик с определенным значением лейблов
a='b'– точное соответствие; все метрики с лейбломa, значение которого равно'b'c='d*'– частичное соответствие; все метрики с лейбломc, значение которого начинается с символа'd'e=['f', 'g*']все метрики с лейбломe, значение которого равно'f'или начинается с символа'g'lines: - expression:
rate(EXPR)#пример: python cpu_user- Скорость изменения значений для всех метрик, указанных в
EXPR lines: - expression:
counter_rate(EXPR)#пример: python cpu_user- аналогично функции
rate, но с обработкой сброса счетчиков lines: - expression:
sum(EXPR [, ignore_nan=True|False])#пример: all python's cpu_user and cpu_system- сумма всех метрик, указанных в
EXPR - В случае
ignore_nan=Falseконечный результат тоже будет NaN, если хотя бы одно из значений равно NaN. Значение по умолчанию:ignore_nan=True lines: - expression:
max(EXPR)- expression:min(EXPR)- expression:std(EXPR)#стандартное отклонение - expression:average(EXPR)#то же, что и mean - expression:mean(EXPR)#пример mean load average- для каждого значения метрики, указанной в
EXPR, выполняется функция агрегации lines: - expression:
sum_by(label_name, [other_label,] EXPR)#пример processes cpu usage - expression:max_by(label_name, [other_label,] EXPR)- expression:min_by(label_name, [other_label,] EXPR)- expression:std_by(label_name, [other_label,] EXPR)#стандартное отклонение - expression:mean_by(label_name, [other_label,] EXPR)#то же, что и average - expression:average_by(label_name, [other_label,] EXPR)#пример mean load average- группировка всех метрик в
EXPRпо значению лейблаlabel_name; все метрики из одной группы агрегируются в одну, новую метрику. - Возможно использование параметра
ignore_nan=False|True; поведение аналогичноsum lines: - expression:
win_sum(window_size_in_seconds, EXPR)- expression:win_mean(window_size_in_seconds, EXPR)#то же, что и win_avg - expression:win_min(window_size_in_seconds, EXPR)- expression:win_max(window_size_in_seconds, EXPR)- expression:win_std(window_size_in_seconds, EXPR)- expression:win_avg(window_size_in_seconds, EXPR)#пример mean load average с окном в 1 час- Применяются функции
sum|mean|min|max|stdдля каждой метрики, указанной вEXPR, со смещением, равнымwindow_size_in_seconds. См. Скользящая средняя lines: - expression:
cum_sum(EXPR)#пример- Кумулятивная сумма для всех метрик в
EXPR. lines: - expression:
top(N, EXPR[, include_other=true|false][, by="exp"|"sum"|"max"])#пример: 5 процессов с наибольшим использованием CPU - expression:bottom(N, EXPR[, by="exp"|"sum"|"max"])- Показать top|bottom
N(N максимальных|минимальных значений) для каждой метрики, указанной вEXPR, выбранных на основеexp|ews(экспоненциально взвешенной суммы) илиsumилиmaxдля каждой точки lines: - expression:
filter_with(EXPR, FILTER_EXPR)#пример: использование памяти долгоживущими процессами- фильтр для метрик, указанных в
EXPR; возвращает только метрики с ненулевым (или не-NaN) значениемFILTER_EXPR. lines: - expression:
const(v[, label="value", ...])#пример- константная метрика со значением
vи дополнительным лейблом, который можно использовать в легенде lines: - expression:
time()- возвращает timestamp по оси X в качестве значения Y
lines: - expression:
from_string("1,2,3,3,2,1,", [,repeat=false] [,sep=' '] [,label="value", ...])#пример- конструктор метрик из строки, например:
"1,2,3,3,2,1,". Здесь каждый элемент равен значению метрики за соответствующую минуту lines: - expression:
defined(EXPR)#пример: все процессы- возвращает
1, если у метрики, указанной вEXPR, есть значение в данной точке, или0, если значение метрики NaN lines: - expression:
replace(old_val, new_val, EXPR)#пример - expression:n2z(EXPR)#shortcut for "replace(nan, 0, EXPR)" - expression:zero_if_none(EXPR)#shortcut for "replace(nan, 0, EXPR)" - expression:z2n(EXPR)#shortcut for "replace(0, nan, EXPR)" - expression:zero_if_negative(EXPR)- expression:none_if_zero(EXPR)#shortcut for "replace(0, nan, EXPR)" - expression:remove_below(EXPR, value)- expression:remove_above(EXPR, value)- expression:clamp_min(EXPR, min)- expression:clamp_max(EXPR, max)- устанавливает новое значение
new_valвзамен старогоold_val lines: - expression:
sum_by(label, [other_label,] metric(..)) / max_by(label, [other_label,] metric(.))- expression:sum_by(label, [other_label,] metric(..)) * sum_by(label, [other_label,] metric(.))- expression:sum_by(label, [other_label,] metric(..)) - min_by(label, [other_label,] metric(.))- возвращает результат арифметических операций
/,*или-для всех пар метрик (одной с левой стороны и одной с правой стороны), у которых полностью совпадают наборы лейблов и их значений lines: - expression:
sum_by(label, [other_label,] metric(..)) / EXPR- expression:min_by(label, [other_label,] metric(..)) * EXPR- expression:max_by(label, [other_label,] metric(..)) - EXPR- производится
/ (деление) на значение EXPRили* (умножение) на значение EXPRили- (вычитание)значения EXPRдля каждой метрики слева, полученной в результате расчетаXXX_by(label, ...)
Настройка отображения легенды:
lines: - expression: metric(...) legend:
'%s'- в легенде отображаются пары
label_name:label_valueдля каждой линии lines: - expression: metric(...) legend:
'%(label_name)s anything'- в легенде отображаются
label_value anythingдля каждой линии
Настройка цвета линии:
lines: - expression: metric(...) color:
'#81ff22'- expression: metric(...) color:'red'- задает цвет линии
lines: - expression: metric(...) colors:
['#80AB00', 'red', 'rgb(127,0,20)', 'hsla(100,10%,20%,0.8)']- циклическое переключение по списку цветов
lines: - expression: metric(...) colors:
/regex.*/: '#fff' /regex2/: 'gold'- задает цвет линий, удовлетворяющих regexp
lines: - expression: metric(...) options: colors:
semaphore#OR colors:semaphore inv- заливает все ранее неокрашенные линии градиентом от
redдоgreen - или от
greenдоred, если задана опцияsemaphore inv
Сортировка:
lines: - expression: metric(...) options: sort:
alpha|num- сортировка всех строк в легенде в алфавитном порядке или по значениям (режим по умолчанию)
lines: - expression: metric(...) options: sort:
['fixed', 'order', 'for', 'legend', 'items']- фиксированный порядок для отображения элементов легенды
lines: - expression: metric(...) options: sort: ... order:
DESC- убывающий порядок сортировки
Синтаксис сортировки во всплывающей подсказке:
lines: - expression: metric(...) options: tooltip: sort_order:name|-name|value|-value-
Сортировка строк во всплывающей подсказке(по умолчанию без сортировки):
- в алфавитном(
name|-name). - по значениям(
value|-value)
- в алфавитном(
Captions:
lines: - expression: metric(...) - expression: metric(...)
title: 'some %(label_name)s'- название графика
lines: - expression: metric(...) - expression: metric(...) options:
y_title: 'some text'- название оси Y
Alerting
Алерты — неотъемлемая часть системы мониторинга. Они позволяют пользователю своевременно узнавать о происходящем.
Настройка уведомлений в Okmeter состоит из двух частей: в части triggers настраиваются правила, определяющие, когда отправляется уведомление. Часть notifications определяет, куда отправляется уведомление
Okmeter предлагает большое количество преднастроенных триггеров. Также можно создавать свои триггеры или переопределять преднастроенные.
Настоятельно рекомендуем тестировать изменения в настройках triggers или notifications, чтобы убедиться, что уведомления срабатывают тогда, когда это необходимо.
Самый простой способ тестирования — перевести триггер в активное состояние. Сделать это можно, например, изменив значение threshold.
Триггер
Ниже приведен пример триггера. Данный триггер проверяет количество ошибок в логах доступа NGINX:
expression: 'sum(n2z(metric(name="nginx.requests.rate", status="5*")))' threshold: '>= 1' severity: critical message: '5xx NGINX %(value).1f per sec' notify_after: 120 resolve_after: 180 notification_config: ops
Для настройки триггеров доступны следующие опции:
expression
Expression содержит выражение, которое будет использоваться для рассчета значения триггера.
Оно состоит из селектора метрики (metric(name="..", label_foo="..")) в включает ряд математических операций.
См. раздел о языке запросов для получения дополнительной информации.
threshold
Threshold - значение, с которым сравнивается значение триггера, полученное в результате выполнения запроса, указанного в expression, и операции сравнения. Если условие в операции сравнения истинно, триггер становится активным.
Допускаются следующие операции сравнения: <, <=, >, >=.
severity
Критичность триггера. Для данного поля может иметь значение: critical, warning или info.
info никогда не отправляются.
message
Message — поле, содержащее текстовое описание триггера. Оно будет добавлено в уведомление. С помощью языка форматирования в это поле можно добавить результаты выполнения запроса и лейблы.
Например, чтобы включить в сообщение конкретный код ошибки, который привел к срабатыванию триггера, измените стандартный триггер NGINX следующим образом:
expression: 'sum_by(status, n2z(metric(name="nginx.requests.rate", status="5*")))' message: '%(status)s NGINX %(value).1f per sec'
notify_after / resolve_after
Для игнорирования краткосрочных всплесков можно использовать параметры notify_after и resolve_after.
notification_config
notification_config — данное поле задает каналы (подробней про настройку каналов доставки уведомлений в разделе: Уведомления), по которым будет отправлено уведомление. По умолчанию все уведомления доставляются по email и sms и для этого не требуется дополнительных настроек.
Чтобы изменить поведение по умолчанию, создайте notification_config с именем default. При этом задавать для каждого триггера notification_config: default не требуется, поскольку notification_config с именем default используется для них по умолчанию.
Чтобы отключить уведомления для триггера, укажите: notification_config: off.
Уведомления
В notification config могут содержаться следующие поля:
renotify_interval: 600 notify_resolve: on oncalls: # email and sms - admin_1 - admin_2 - boss slack_url: https://hooks.slack.com/services/XXXX/XXXX/XXXXXXXX slack_channel: '#ops' telegram_chat_id: -XXXXXXXX opsgenie: api_key: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX prometheus: url: http://HOST:PORT/api/v1/alerts basic_auth: username: XXXX password: XXXX
renotify_interval
renotify_interval — задает частоту повторной отправки уведомлений для активных триггеров. Отправка уведомлений (независимо от значения этого поля) прекращается, если триггер перестал быть активным или для него выставлено значение acknowledged или resolved
notify_resolve
notify_resolve — определяет, нужно ли отправлять уведомление, когда триггер изменил свое состояние на неактивное.
oncalls
oncalls — определяет список пользователей, которые получат уведомления. Адреса электронной почты и телефоны пользователей можно задать на странице contacts. Контакты соотносятся по полю Name на странице notification_contacts.
Если не задано ни одного notification configs, уведомления будут отправлены всем пользователям, для которых разрешены уведомления на странице notification_contacts.
slack
Для отправки уведомлений в Slack необходимо создать WebHook в настройках Slack'а.telegram
Для отправки уведомлений в Telegram необходимо:
@OkmeterBot.
telegram_chat_id указать ID чата.
Для получения ID чата можно воспользоваться нашим ботом. Добавив @OkmeterBot в чат, выполните следующую команду: /chat_id@OkmeterBot
opsgenie
Чтобы отправлять уведомления в Opsgenie, создайте новую интеграцию API (Rest API over JSON) в настройках Opsgenie и укажите полученный API key в поле api_key.
Внимание: При использовании EU Opsgenie необходимо дополнительно указать api_url: api.eu.opsgenie.com.
alertmanager
Чтобы отправлять уведомления в Prometheus Alertmanager, задайте следующие поля в секции Prometheus:- url — адрес вашего Alertmanager'а.
- basic auth — данные Basic Auth для вашего Aletrmanager'а. Настоятельно рекомендуется всегда включать Basic Auth для инсталяции Alertmanager'а.
- username — имя пользователя.
- password — пароль.
Удаление Okagent
-
sudo /etc/init.d/okagent stop -
sudo service okagent stop -
sudo systemctl stop okagent.service && sudo systemctl disable okagent.service
sudo rm -rf /usr/local/okagent /etc/init.d/okagent
Техническая поддержка
Всегда рады ответить на любые ваши вопросы: support@okmeter.ru.